
今回レビューするのは、「Excelで考える統計学」山中 馨、天谷 永、望月 雅光 著 創成社です。
本書は、統計学の本ですが、その実例をExcelで検証して理解しようという本です。また、他の本とはことなり、「例題」ー「回答」形式になっているのも特徴です。
正規分布
「正規分布」は以前にもやっていますが、ここでは正規分布の使い方・運用を主眼において説明して行きたいと思います。
例題:
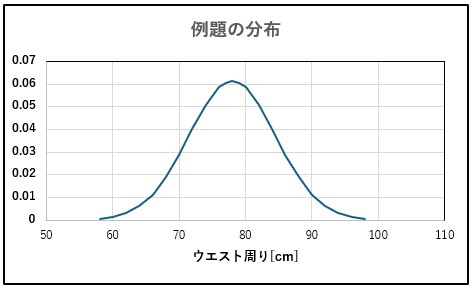
日本でのメタボリックシンドロームの診断基準は男性ではウエスト周り85cm以上である。
いま,成年男性のウエスト周りの分布は平均μ=78.0cm,標準偏差σ=6.5cmの正規分布に従うとき,メタボリックシンドロームと診断される男性の割合はどれ程か。
下図にこの日本の成年男性のウエスト周りの正規分布図を示します。
標準正規変数 z は、以下の式で定義されます。
z =
この式を適用することで、zは正規分布に従う指標になります。下図に標準正規分布を示します。
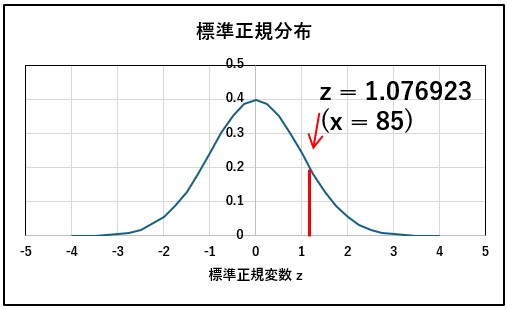
診断基準 x=85.0 とすると標準正規変数zは次の式に従って、μ=78.0, σ =6.5を代入すると z= 1.076923 となります。したがって正規分布のzより大きい割合は次のように求められます。
つまり、ウエスト周り x=85cm は、標準正規分布に当てはめると、横軸 z = 1.076923になります。例題で問うているメタボリックシンドロームは、ウエストサイズ x = 85cm(z = 1.076923)以上になりますから、赤線の右側の部分の面積になります。
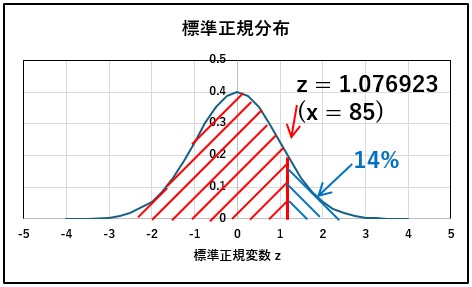
これは、Excel関数の「NORM.S.DIST(z,TRUE)」からもとめられます。「NORM.S.DIST(z,TRUE)」は、「-∞~ NORM.S.DIST(z,TRUE)」を現しますので、赤線の右側の面積は、「1 – NORM.S.DIST(1.076923)」になります。
この値を計算すると、「1 – 0.859245 = 0.140756」になりますので、日本の成人男性でメタボリックシンドロームと診断される人の割合は、約14%になります。
なぜ、標準正規分布に変換するのか?
なぜ、標準正規分布へ変換するのかというと、他の分野の中で流体力学でいうと、「クヌーセン数」や「レイノルズ数」への変換に似ているかも知れません。
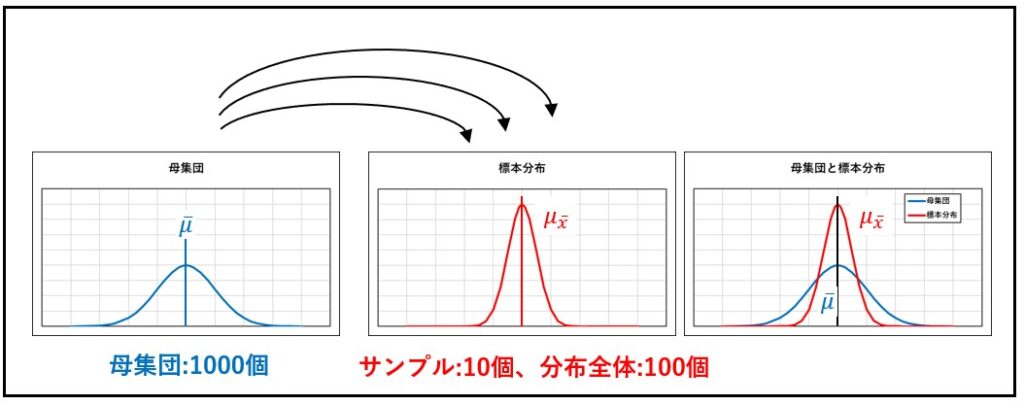
標本分布
母集団から無作為抽出で標本を抽出する場合には、同じ標本が得られることはまず考えられません。同じ目的の世論調査をA 新聞社とBテレビ局が行ったとしても、その結果がまったく同じであることはなく、異なっていても何ら不思議ではありません。
したがってA 新聞社の出した標本平均値 (XA )とBテ レビ局が求めた標本平均値(XB ) とは異なり、このような調査が多くの報道機関 で行われた場合、さまざまなが現れます。つまり、標本平均値自身が 統計量(statistics)として分布することがわかります。
推測統計学では、たまたま得られた標本から母集団の性質を推測しなければなりません。そこでまず、この例題のように、ある母集団から抽出して標本となる可能性のあるすべての場合を対象としてその標本平均値の振る舞いを調べるために、その確率分布をつくります。
これを「標本分布(sample distribution)」といいます。この標本分布の性質を明らかにすれば 標本から母集団のパラメータ (parameter, 母平均や母分散、母標準偏差などのこと) が推測できる手がかりが得られるわけです。
(1) 標本分布の平均値μxは母集団の平均値μに等しい。
(2) 標本分布の標準偏差σxは、母集団の標準偏差σより小さい。
標本分布の標準偏差が母集団の標準偏差より小さくなるのは、次のように考 えればわかります。例えば無作為抽出でたまたま大きな観測値が得られたとしても、他の観測値もそのような大きな値になる確率は低く、抽出されやすい (確率の高い)部分、つまり母集団分布の山の部分(平均値の近傍)の値が得られるはずです。
すると、それらの平均値は異常値の影響が薄まって平常値に近くなるはずです。したがって平均値の分布(標本分布)のばらつきは母集団の平均値の近い所に集まってばらつくはずです。
このようにして標本分布の標準偏 差は母集団の標準偏差よりも小さくなるであろうと推測できます。
標本分布の平均値,分散と標準偏差の理論値 母集団のパラメータ(平均μ,分散σ2,標準偏差σ)と標本分布のパラメータ (平均μx ,分散σx 2,標準偏差σx )の理論的な関係は次の式のように表されます。 まず、標本分布の平均値は
μx = μ
となります。
次に、標本分布の分散は有限母集団と無限母集団の場合に分けられます。
無限母集団 無限母集団の場合、正規母集団の場合には
となります。 なお、上記の有限母集団の場合でもNが十分大きければNについての分数 の部分はほぼ1に等しく、無限母集団の式が適用されます。いずれの場合にも 分母に”があり、標本の大きさが大きくなれば標本分布の分散は小さくな り、平均値の周りに集まってくることがわかります。
標準偏差はいずれの場合でも
で与えられます。
ヒストグラム
2. 最大値と最小値を求める。
(1)次にこれらのデータの最大値と最小値を求めるために Excel 関数の MAX ()と MIN ()を使います。
① 「数式バー」にある「」 アイコンをクリックするか、もしくは 「リボン」の「数式」→「関数ライブラリ」 「関数の挿入」を選び、 「関数の挿入」ウインドウを出します。
② 「関数の分類」を「統計」として最大値の場合は MAX, 最小値の 場合は MIN を選びクリックし「OK」ボタンを押します。
③ 「数値1」の欄にA列のデータを上から下までマウスでドラッグし てデータ範囲を入力します。欄には「A1:A20」の表示が出ます。 または、A1:A20 と直接キーボードから入力しても同じです。
④ 次に「OK」ボタンをクリックすると MAX の場合はデータの最大 値を、MINの場合は最小値が表示されます。最大値は24600,最 小値は2468 と求められます。
別の方法として、「データ」 「分析」からアドインした「分析ツール」を 選び「データ分析」 ウインドウを出します。「基本統計量」を選び、入 カウインドウを出します。
「入力範囲」にデータ全体をマウスでクリックして指定します。この場 合は A1:A20 が表示されます。「統計情報」にマウスでチェックを入れ た後、出力先に出力情報を表示させたい最初のセルをクリックします。 空白のセルで良いので、例えばC1とします。「OK」ボタンを押しま す。結果を見ると最大が24600, 最小が2468 となっています。
次に電話料金を2000円間隔で区切ります。表1のように「以上」と「未 満」とタイトルをつけた2列を作ります。
(1)一例として2000円以上 4000円未満,4000円以上 6000円未満などと区 切って最高値を26000円とします。表1を参照してください。
●
(2) 「以上」の列は 2000,4000 と入力してフィルハンドルを使ってマウスド ラッグして24000まで作ります。
(3) 「未満」の列は同様に 4000から2000間隔で、マウスドラッグで26000 まで作ります。
4. 次に2000円ごとの区分間隔(「階級」と呼ぶ)の真ん中の値を「階級値」と して次の列に加えます。
(1)行と列が表1のようなセル配置であると仮定して、最初の行の階級値は G2 に次の式によって求めます。セル番号の入力は、そのセルをマウス クリックすることで行ってください。 =(E2+F2)/2
(2) 最初の行が求まれば、後はフィルハンドルを使ってマウスドラッグに よって最終行までの階級値を求めます。
5. 度数のカウントの仕方 2000円ごとのそれぞれの階級の額を支払っている学生の数(「度数」と呼ぶ) を数えます。
(1)度数を数えるには関数の COUNTIFS を用います。
●
①最初に「度数」という項目を作ります。
② 度数の列の最初のセルをクリックしておきます。「関数の分類」の 「統計」からCOUNTIFS を選び、COUNTIFS の入力ウインドウを 出します。
③「検索条件範囲 1」は絶対参照の範囲 $A$1:$A$20 とし(マウスドラッ グで範囲を指定後にファンクションキー F4を押す),「検索条件1」には [“> = ”&E2」とします。ここで「E2」は最初の階級の最低値(つまり「以上」の値) 2000 を示しているセルの番号を仮定しています。したがって、[” > = “&E2」はセル E2に示している2000以上を意 味します。
④次に、「検索条件範囲2」には、同じ範囲を絶対参照として $A$1:$A$20 とし、「検索条件2」には「”<“&F2」とします。ここ で「F2」は最初の階級の最高値 (つまり 「未満」の値) 4000を示して いるセルの番号です。したがって、「”<“&F2」はセル F2に示し ている 4000未満を意味します。
⑤数式バーには「=COUNTIFS ($A$1:$A$20,”>=”&E2,$A$1:$A$20,”< &F2)」と表示されます。Enter キーを押下すれば関数 COUNTIFS は2000以上 4000未満のデータの数をカウントして出力します。
⑥ この後、フィルハンドルを使って最終階級までドラッグしすべての階 級について求めます。このようにして、前頁の表1が得られました。
(2) 度数を数えるにはこの方法以外に直接度数をカウントする方法がありま す。以下の方法については参考資料として章末に後述します。
① 関数 FREQUENCY による方法
② 分析ツールの「ヒストグラム」による方法
6. 最終列の相対度数とは度数の合計でそれぞれの階級の度数を割ったもので す。解説を参照してください。
この表に基づいて携帯電話料金の学生数(度数)の散らばり具合 (「分布」と呼 ぶ)を描いたグラフ (「ヒストグラム」と呼ぶ)が図1です。図をみると階級値 9000円のところをピークにして高い方へ伸びた
Excel によるヒストグラムの描き方
① 描画したいデータ(この場合は表1の「度数」のデータ)をマウスでドラッ グして指定します。
② メニューから「挿入」「グラフ」 → 「縦棒」→「2-D 縦棒」 「集合縦棒」 3 を選択します。
③料金を横軸に表示させるために「グラフツール」 「デザイン」 → 「デー タの選択」を選んで「データソースの選択」ウインドウを出します。 「横(項目)軸ラベル」の「編集」ボタンをクリックして、「軸ラベルの 範囲」に階級値の列をマウスでドラッグして指定します。「OK」ンを押してウインドウを閉じます。
④ 横軸のラベルは、グラフの横にある[+]アイコンをクリックし、「軸ラ ベル」にチェックを入れます。グラフに現れた横軸ラベルの「軸ラベ ル」の部分に「料金(円)」と入力します。
⑤縦軸ラベルは「軸ラベル」の部分に「度数」と入力します。 同様にして「グラフタイトル」の部分に「携帯電話料金」を入力しま す。もし「グラフタイトル」がなければ、アイコンをクリックし、 「グラフタイトル」をチェックします。
⑦グラフの縦棒のどれかをクリックすると「グラフツール」 「書式」の 「現在の選択範囲」で「グラフ要素」を示すボックスが「系列1」とな ります。このグラフ要素ボックスをマウス操作で「系列1」と選択しても同じです。
⑧ボックスの下の「選択対象の書式設定」をクリックすると「データ系列 の書式設定」が画面の右に現れます。
⑨「系列のオプション」の「要素の間隔」をスライダーで「0%」にします。
➉ 「系列のオプション」にある「塗りつぶしと線」のアイコンをクリック します。「枠線の色」を「線(単色)」とし、色を黒に指定して、閉じます。
順列
順列とは、いくつかのものを順序をつけて並べることです。英語では、”Permutation”というため、順列を現す記号は、「P」になります。
例:
5個から3個選んで順序の総数は、
5P3 = 5 × 4 × 3 = 60 個
になります。
組合せ
異なるn個の物の中からr個取り出した時の組み合わせの数のこと(順序は考慮しない)。
5個から3個のものを選んで並べる組み合わせの数
5C3 = = 10
① nCr = =
② nCr =


コメント